如果我们现在重新加载页面,您将看到日志中填充了六个新的请求。 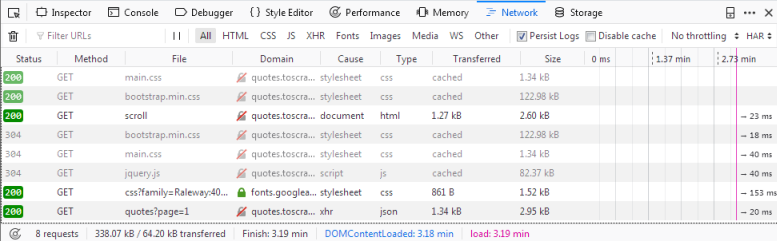 在这里,我们可以看到在重新加载页面时发出的每个请求,并且可以检查每个请求及其响应。因此,让我们找出我们的报价来自哪里: 首先单击带有名称的请求 你应该在里面看到什么 如果我们点击这个请求,我们会看到请求的URL是 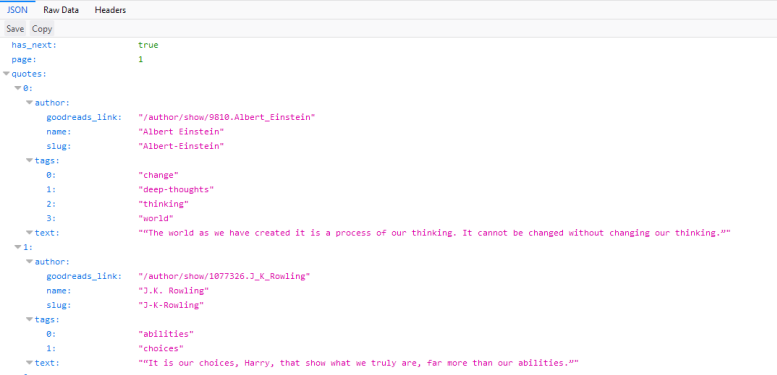 有了这个响应,我们现在可以轻松地解析JSON对象,并请求每个页面获取站点上的每个引用: import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse) |
Archiver|手机版|笨鸟自学网 ( 粤ICP备20019910号 )
GMT+8, 2026-5-3 19:47 , Processed in 0.018071 second(s), 18 queries .